背景
随着LLM的发展,TTS也从传统的phoneme → mel-spectrogram → waveform路径转向phoneme → discrete code → LM → waveform。 VALL-E便是这个背景下的产物。
论文:https://arxiv.org/abs/2301.02111
结果展示页面:https://www.microsoft.com/en-us/research/project/vall-e/
代码(非官方):https://github.com/enhuiz/vall-e
Audio Codec Encoder
要得到discrete code就得使用离散化的工具,以获得离散化的acoustic unit用于LM训练。在VALL-E中用到的是EnCodec,而EnCodec以SoundStream为基础。
首先对音频编解码的工作流程进行介绍,如下图所示:
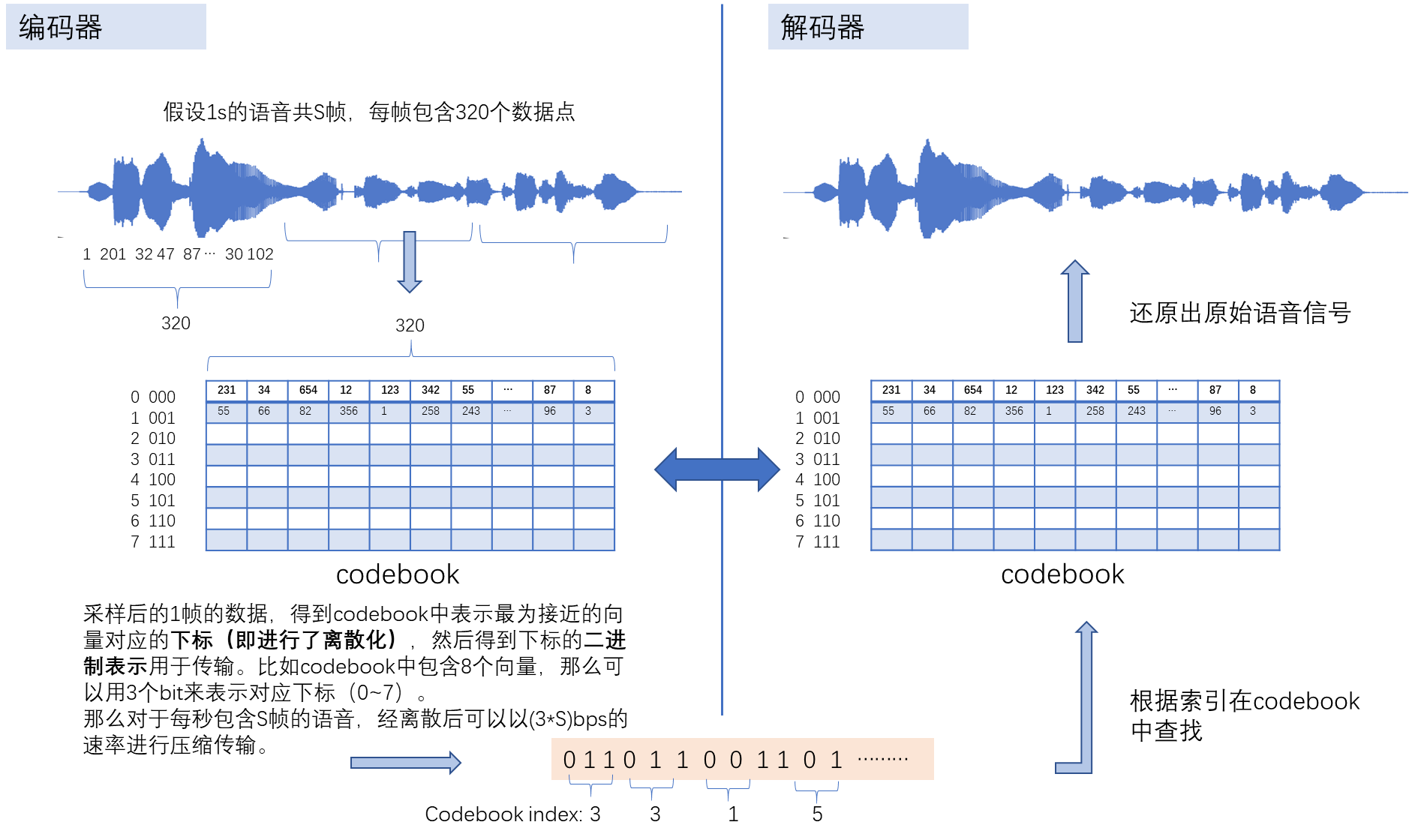
- 假设音频采样率24k, 每帧包含320个采样点,则每秒有S = 24000 / 320 = 75帧;
- 如果codebook中只包含8个向量,那么以75*3bps的速率就可以传输离散化后的语音表示(传递的是codebook的下标);
- 但是这个时候用8个向量来表示所有语音的话,解码后的语音会非常失真,所以codebook中的向量往往会多很多。当需要更高传输速率的时候,比如在6kbps的时候,可以用80bit来表示codebook中的一个下标,这时codebook中的向量的数量可以达到2^80个,这是不可接受的。所以就有了SoundStream的提出。
SoundStream
SoundStream提出Residual Vector Quantitation (RVQ)来平衡codebook大小和比特利用率,其结构如下:
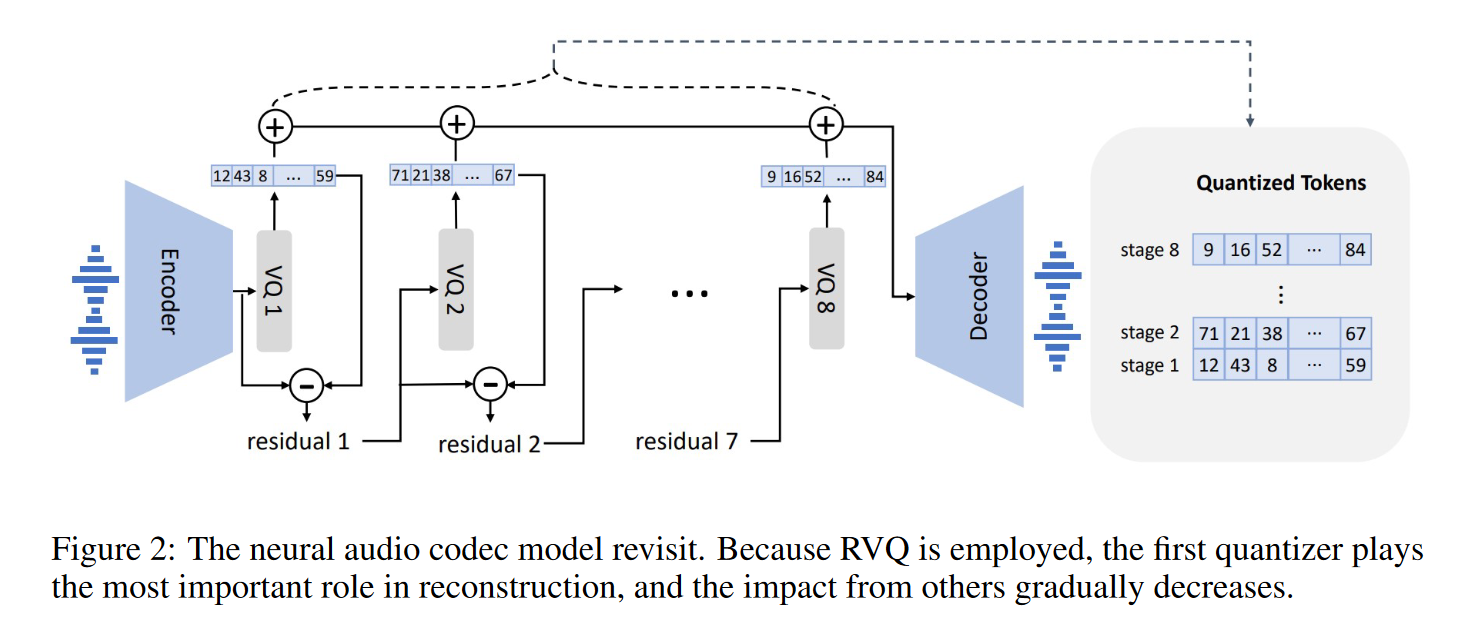
SoundStream使用多个quantitation block对应多个codebook,它们之间有残差连接,重要性不同;若使用8个codebook,则每个codebook可利用10 bits, 大小为2^10=1024, 可接受。
EnCodec
VALL-E中用到的离散模块是基于SoundStream的改进版EnCodec,其模型结构图如下:
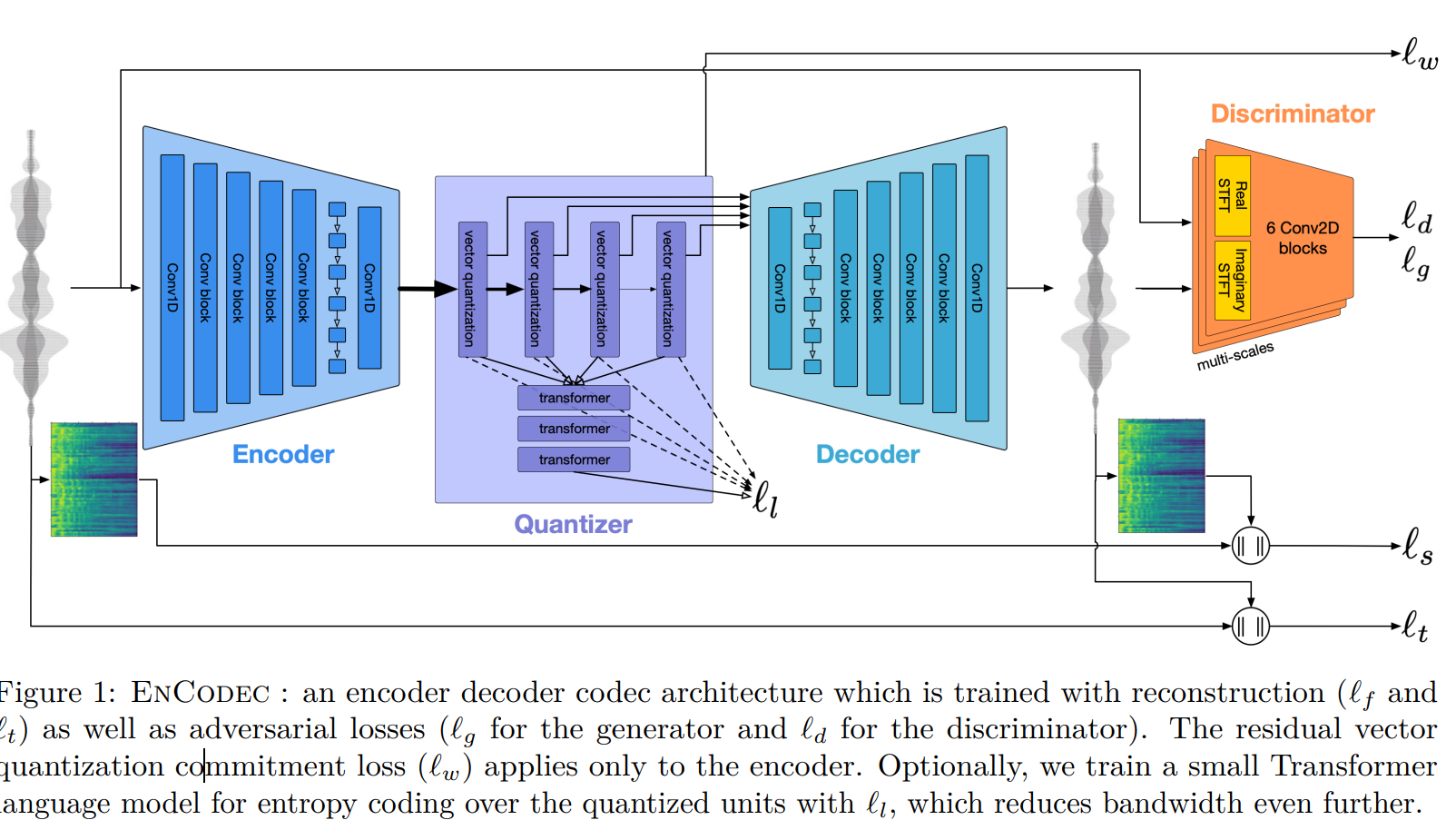
相比SoundStream有以下改进:
- 加入了之前忽略的Waveform重建loss;
- 引入了一个小的语言模型,该语言模型根据t时刻的RVQ向量,预测t+1时刻的RVQ向量,用于提前解码下一刻的语音;
VALL-E模型结构
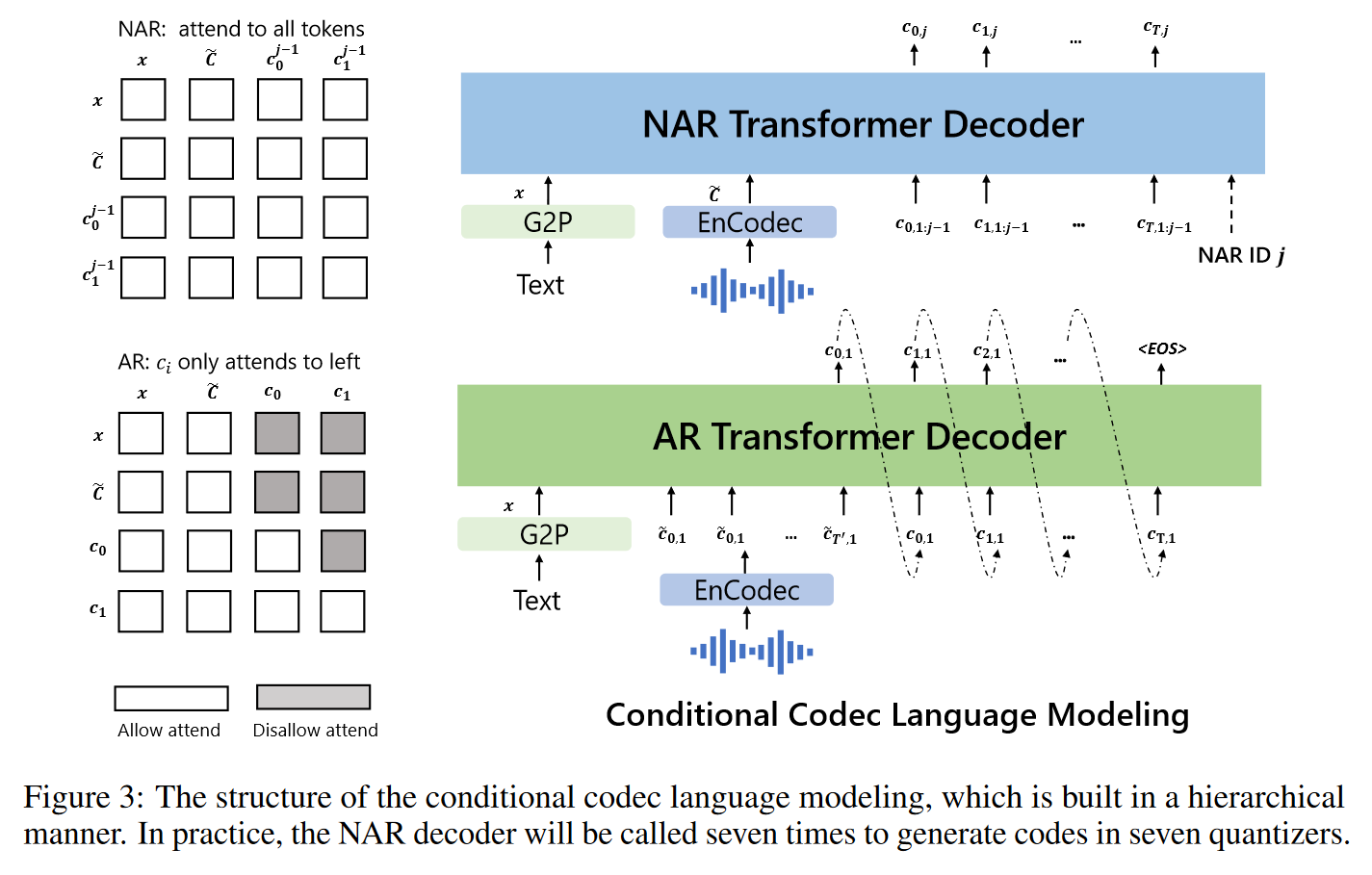
模型整体框架如图:
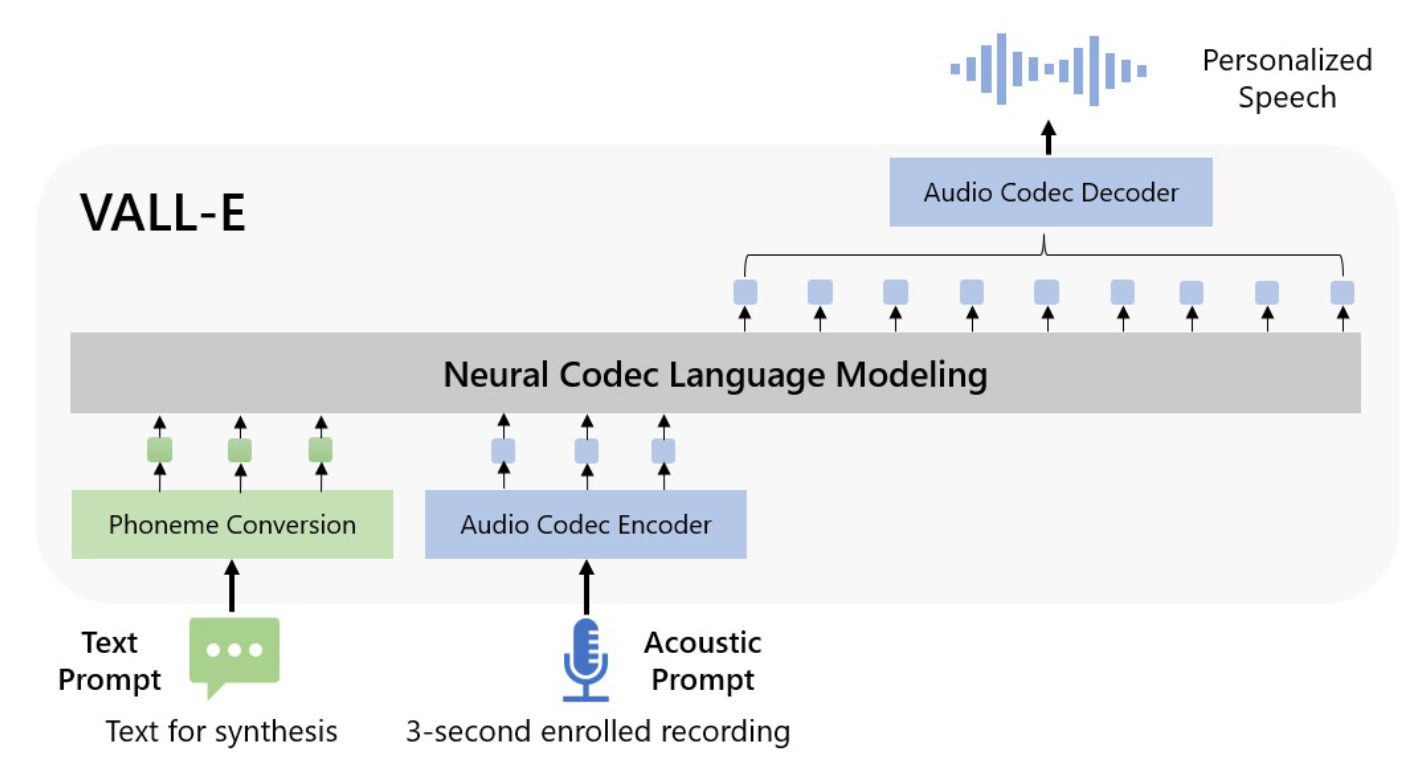
- 预训练阶段:Encodec提取的离散tokens + ASR得到的text对应的phoneme tokens用LM的方式进行预训练。
- 微调阶段:分别使用文本 / 音频prompt,分别控制语音合成的内容与风格。
LM是由多个Transformer Decoder层组成。每个decoder对应RVQ中的一层,对于对重要的第一层RVQ,VALL-E使用一个自回归的结构进行解码预测;随后,后续每层RVQ的tokens基于上一层的RVQ tokens,使用非自回归的transformer encoder进行解码预测(加快运行)。
最终,将acoustic tokens输回Encodec,生成语音。