摘要
本文介绍 Tacotron 2 ,一个神经网络架构的语音合成模型。该系统由一个seq2seq的特征预测网络和基于 WaveNet 的 vocoder 构成。该模型的 MOS 值可以达到4.53,非常接近专业录音的 4.58。为了验证使用 mel spectrugram 作为 vocoder 输入的有效性,我们和 linguistic, duration, 以及 F0 特征作为输入进行了对比。此外,我们进一步展示了使用 compact acoustic intermediate representation 即 mel spectrugram 作为输入可以大大减小 WaveNet 的参数量。
前置知识
-
Tacotron2 的重要贡献在于 neural acoustic + neural vocoder, 神经网络以LSTM和CNN为主,缺点是自回归的模型生成速度较慢;
-
Tacotron 与 Tacotron 2 的区别在于:
Tacotron = autoregressive seq2seq + Griffin-Lim reconstruction
Tacotron2 = autoregressive seq2seq + modified WaveNet
-
前有 Deep Voice 3 以及 Char2Wav 使用 seq2seq + neural vocoder,但是前者的效果不及本文的方法,后者使用中间表示而不是 mel-spectrogram 作为 vocoder 的输入
模型结构
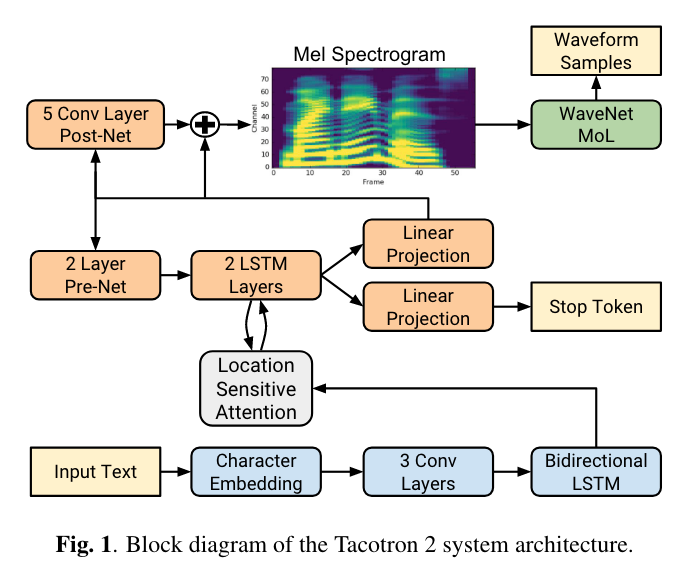
如图1,模型由两部分组成:(1) seq2seq的特征预测网络 (feature prediction network), 得到 mel spectrugram 特征。(2) 基于 WaveNet 的 vocoder ,用于从 mel spetrugram 得到 waveform。
Why Mel Spectrogram
这部分介绍了为什么选择梅尔谱作为预测的特征(这种选择也成为后续众多TTS工作的常规操作),而不是预测 waveform:
- smoother than waveform,easizer to train
- emphasizing details in lower frequencies, which are critical to speech intelligibility, while de-emphasizing high frequency details, which are dominated by fricatives and other noise bursts and generally do not need to be modeled with high fidelity
短时傅立叶变换之后是linear-frequency spectrogram, 再经过梅尔滤波 (nonlinear transform) 之后得到 mel spectrugram。
Spectrogram Prediction Network
特征预测网络由带有注意力机制的encoder decoder组成。encoder包含 Character Embedding、CNN、BLSTM三部分,把字符序列转换成隐层特征表示,然后提供给decoder用于特征预测。Character Embedding 的输出是 512 维,CNN 的 kernel size 是 5x1,得到的隐层表示纬度也是512。
与普通的加性注意力机制有所不同的是,作者使用位置敏感 (location-sensitive) 的注意力机制,这种方式可以减少某些和位置相关的错误情形,比如跳词和重复。location-based, content-based 以及 hybrid attention mechanisms 的不同在于注意力得分 $\alpha_i$ 的计算方式:
- location-based: $\alpha_i = Attend(s_{i-1},\alpha_{i-1})$
- content-based: $\alpha_i = Attend(s_{i-1},h)$
- hybrid attention: $\alpha_i = Attend(s_{i-1},a_{i-1},h)$
decoder 是自回归的循环神经网络,每一个时间步利用 encoder 的输出产生一帧梅尔谱。当前时刻产生的梅尔谱经过 pre-net 和 attention context vector 进行拼接用于得到 attention hidden,新的 attention context vector 和 decoder hidden进行拼接经过一个线性层得到下一帧的预测,对应的代码如下:
1 | cell_input = torch.cat((decoder_input, self.attention_context), -1) |
然后 predicted spectrogram frame 会经过 post-net(卷积网络)得到一个残差,和 predicted spectrogram frame 相加后得到最终的预测,这样做的目的在于 improve the overall reconstruction。
此外,还会同时训练一个 “stop token” predictor,以便在推理时告诉模型什么时候停止生成。
WaveNet Vocoder
与原始 WaveNet 不同的是,本文使用 WaveNet 将梅尔谱转换成 waveform。此外原始的 WaveNet 预测 8-bit audio,音频质量较差,本文使用 PixelCNN++ 中的 discretized mixture of logistics 方法将 bit 数提升至 16。
实验与结果
数据集
使用的是内部的单说话人24.6小时的训练数据,在正则后文本上进行训练。
评估
为了评估模型的表现,和各种之前的模型进行对比,包括参数化的 (Parametric) 、拼接 (Concatenative) 的方法以及基于 Linguistic 的 WaveNet。结果表明Tacotron 2具有更好的表现,基于mel spectrugram 的 WaveNet 也优于基于 Linguistic 的 WaveNet 表现;

当对合成的语音与Ground Truth进行并行评估,打分 [-3,3],-3表示差很多,3表示很好,得到的结果如图2,整体平均得分−0.270 ± 0.155表明,合成的语音略差但非常接近。
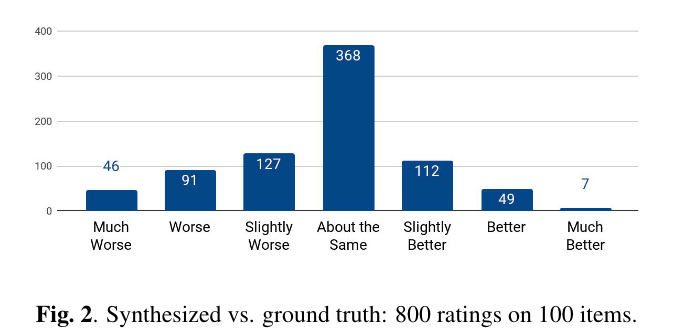
对100个句子的错误模式进行分析,其中6条句子出现发音错误,1条出现跳词,23条韵律不自然,1条 “stop token” 预测错误。
37条集外测试集上的结果表明,基于mel spectrugram的合成模型和基于linguistic的合成模型表现接近(4.148 ± 0.124 vs 4.137 ± 0.128),评测人员表示基于mel spectrugram的合成模型更加自然、接近人类发音,但对人名等发音较为困难。这也表明端到端的方法往往需要根据场景不同用不同的数据进行训练。
消融实验
Predicted Features versus Ground Truth
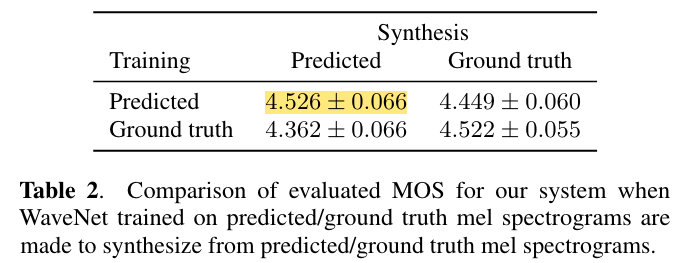
特征预测网络和声码器是两个分开的模型,所以可以单独进行训练,一共替代的方法就是使用ground truth 训练vocoder,而不是特征预测网络预测的mel spectrugram。结果如下表,正如期望的那样,在同一种特征上训练和预测表现的更好(domain match)。当使用ground truth进行训练,predicted进行合成并没有表现更好,这是因为predicted features往往比较oversmoothed and less detailed than the ground truth,vocoder并没有从这种特征中学习如何合成高质量语音。
Linear Spectrograms

如表3,使用mel spectrugram优于linear spectrugram模型的表现。
Post-Processing Network
Post-Processing Network的目的是为了incorporate past and future frames to improve the feature predictions,但是本文用了 WaveNet 作为 Vocoder,本身是含有卷积层的,那么还有必要在使用PostNet吗,对此作者进行了实验,结果表明使用 PostNet 会获得更好的模型表现(4.429 ± 0.071 vs. 4.526 ± 0.066)。